
Co to jest Spring WebFlux?
Spring WebFlux jest to reaktywny moduł Spring’a, pozwalający na zastosowanie reaktywnych strumieni oraz użycie nieblokujących się kontenerów aplikacji takich jak Netty lub Undertown. Oczywiście możemy też skonfigurować Tomcat’a jako kontener nieblokujący, lecz wcześniej wymienione serwery aplikacji zostały zaprojektowane od podstaw tak, aby można było je wykorzystywać do rozwiązań typu non-blocking.
Spring WebFlux jest to implementacja paradygmatu programowania reaktywnego w Spring Framework 5. Jeśli nie wiesz, czym jest ten paradygmat, to zanim przejdziesz dalej, zachęcam Cię do przeczytania artykułu na temat programowania reaktywnego, w którym dowiesz się więcej na jego temat.
Ok, skoro już wiesz, czym jest paradygmat programowania reaktywnego, to przejdźmy do jego implementacji w Spring’u. Cały moduł Spring WebFlux został oparty o Project Reaktor. Jest to biblioteka stworzona do programowania reaktywnego w języku Java.
Dodanie Spring WebFlux do projektu
Maven
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-webflux -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<version>2.3.1.RELEASE</version>
</dependency>
Gradle
// https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-webflux
compile group: 'org.springframework.boot', name: 'spring-boot-starter-webflux', version: '2.3.1.RELEASE'
Strumień Flux
Jest to reaktywny strumień (Publisher), który może wyemitować od 0 do N elementów. Implementuje on interfejs Publisher<T> i może posiadać jedną z trzech wartości:
- element – obiekt
- sygnał sukcesu
- sygnał błędu
Poniżej znajduję się schemat działania strumienia Flux:

Przykład użycia strumienia Flux
Utwórzmy klasę Person, która będzie posiadać informacje o imieniu oraz wieku osoby.
public class Person() {
public int age;
public String name;
// constructor
// getters and setetrs
}W kolejnym kroku dodajmy kontroler, który będzie udostępniał endpoint „getRandomPersons” typu GET. Będzie on zwracał listę obiektów typu Person z losowymi danymi.
@RestController
public class WebFluxConstructor {
@GetMapping("/persons")
private Flux<Person> getAllPersons() {
return Flux.just(new Person(new Random().nextInt(), UUID.randomUUID().toString()),
new Person(new Random().nextInt(), UUID.randomUUID().toString()),
new Person(new Random().nextInt(), UUID.randomUUID().toString()));
}
}Po uruchomieniu aplikacji widzimy, że nie została ona uruchomiona na serwerze Tomcat, jak to się dzieje standardowo dla Spring Boot, lecz na Netty. Oczywiście wszystko za sprawą WebFliux’a, który to potrzebuje do działania serwera non-blocking.
2020-07-06 15:05:46.234 INFO 30956 --- [ main] o.s.b.web.embedded.netty.NettyWebServer : Netty started on port(s): 8080Po wywołaniu adresu ” http://localhost:8080/persons” w przeglądarce otrzymamy wynik zbliżony do poniższego. Nie jest to typowy response w postaci JSON, lecz strumień danych.
[{"age":-770853828,"name":"3326acf9-1d20-4712-a760-ddefbb1de81e"},{"age":22283567,"name":"22791c71-2d9d-4d29-b37c-841e2b13b7cf"},{"age":1324763993,"name":"12639158-9ecd-4df8-a83e-45d35ce1bec4"}]
Strumień Mono
Strumień Mono jest bardzo podobny do Flux z tą różnicą, że przyjmuje on 0 lub jeden element. Można powiedzieć, że jest to uproszczona wersja Flux. Taki podział na dwa różne strumienie daje programiście możliwość jasnego zdefiniowania czy dana funkcjonalność ma udostępniać jeden lub wiele elementów danego typu.
Schemat działania strumienia Mono został przedstawiony na poniższym obrazku:
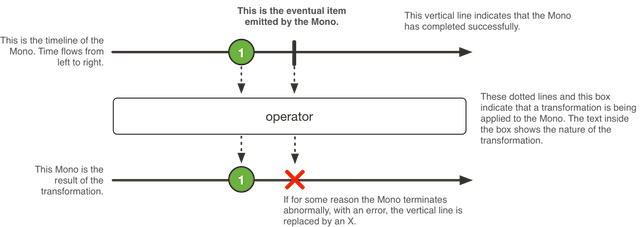
Implementacja endpointu, który wykorzystuję strumień Mono do udostępniania danych, jest bardzo podobna jak ta w przypadku Flux.
Tym razem dodamy dwa parametry, które będą odpowiadać za imię i wiek osoby, której dane chcemy pobrać.
@GetMapping("/person/{name}/{age}")
private Mono<Person> getEmployeeByNameAndAge(@PathVariable String name, @PathVariable int age) {
return Mono.just(new Person(age, name));
}Jako response zapytania ” http://localhost:8080/person/Radek/30 ” otrzymamy obiekt Person:
{"age":30,"name":"Radek"}Podsumowanie
Oczywiście jest to prosta implantacja, która nie wykorzystuje połączenia z bazą danych. Jednak zawsze można zastąpić ciało metod w kontrolerze i udostępniać dane zapisane w bazie. Pamiętajże połączenie do bazy danych także powinno być nieblokujące.
Podobał Ci się ten artykuł? Udostępnij go i podziel się nim ze swoimi znajomymi!