Modele językowe (LLM) zyskały ogromną popularność, znajdując zastosowanie w różnych dziedzinach – od automatyzacji obsługi klienta po zaawansowaną analizę danych. Jednak uruchamianie takich modeli na własnym sprzęcie może być wyzwaniem, zwłaszcza gdy zależy nam na stabilnym, izolowanym środowisku. Instalacja Ollama na Docker pozwala na łatwą konfigurację, uruchamianie i zarządzanie modelami AI bez konieczności instalowania skomplikowanych zależności bezpośrednio w systemie operacyjnym.
Ollama na Docker – Dla kogo jest ta konfiguracja?
To rozwiązanie jest idealne dla programistów AI, badaczy, inżynierów danych oraz firm pracujących nad wdrażaniem modeli AI w swoich aplikacjach. Dzięki użyciu Docker’a można łatwo testować i wdrażać modele, niezależnie od systemu operacyjnego, unikając problemów z niekompatybilnymi wersjami bibliotek czy sterowników.
W jakim celu warto korzystać z Docker’a do uruchamiania modeli LLM?
Lokalna konfiguracja modeli LLM przy użyciu Dockera pozwala na:
- Izolację środowiska – każda instancja modelu działa w swoim kontenerze, nie wpływając na inne aplikacje.
- Łatwe wdrażanie i skalowanie – uruchomienie modelu na różnych maszynach bez konieczności ręcznej instalacji zależności.
- Obsługę GPU – Docker wspiera NVIDIA CUDA, co pozwala na efektywne wykorzystanie kart graficznych w procesie inferencji.
- Oszczędność kosztów – uruchamianie modeli lokalnie zamiast w chmurze redukuje wydatki na API dostawców, takich jak OpenAI czy Hugging Face.
Co będzie potrzebne do rozpoczęcia?
Aby skonfigurować środowisko Docker do pracy z modelami LLM, będziesz potrzebować:
- Docker – platforma do konteneryzacji aplikacji (można pobrać z docker.com).
- Docker Compose – narzędzie do zarządzania wieloma kontenerami jednocześnie.
- Model LLM – np. Llama 3, Mistral, Gemma lub inny kompatybilny model open-source. Listę wszystkich modeli dostępnych dla Ollama znajdziesz tutaj.
Ollama na Docker – uruchomienie kontenera krok po kroku
Instalacja Docker’a
Jeśli jeszcze nie masz Dockera, pobierz i zainstaluj go z oficjalnej strony:
👉 Pobierz Docker
Po instalacji sprawdź, czy działa poprawnie, wpisując w terminalu:
docker --versionTworzenie kontenera z Ollama
Teraz utworzymy kontener Docker’a, który będzie uruchamiał Ollama – narzędzie do obsługi lokalnych modeli LLM. Aby to zrealizować możemy wybrać jedną z dwóch opcji.
Opcja 1: Uruchomienie Ollama bezpośrednio z obrazu
Jeśli chcesz szybko przetestować Ollama, po prostu uruchom poniższą komendę:
docker run -d --name ollama_container -p 11434:11434 ollama/ollamaCo robi ta komenda?
-
docker run -d– uruchamia kontener w tle -
--name ollama– nadaje kontenerowi nazwę „ollama” -
-p 11434:11434– mapuje port 11434 na hosta -
ollama/ollama– używa oficjalnego obrazu Ollama
Po chwili Ollama powinien być dostępny pod adresem http://localhost:11434.
Opcja 2: Tworzenie własnego Dockerfile
Jeśli chcesz mieć większą kontrolę nad konfiguracją, utwórz plik Dockerfile:
FROM ollama/ollama
EXPOSE 11434
CMD ["ollama", "serve"]Następnie zbuduj obraz Dockera:
docker build -t my-ollama .I uruchom kontener:
docker run -d --name ollama_container -p 11434:11434 my-ollamaTestowanie działania kontenera
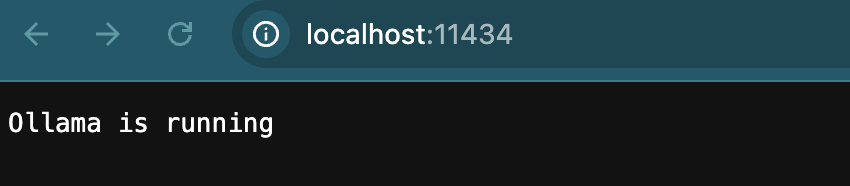
Jeśli po wejściu w przeglądarce na adres http://localhost:11434 zobaczysz komunikat „Ollama is running”, oznacza to, że Twój kontener z Ollama działa poprawnie!
Ollama na Docker – Pobranie modelu LLM
Modele LLM (Large Language Models) to zaawansowane algorytmy sztucznej inteligencji stworzone do przetwarzania i generowania języka naturalnego. Są one trenowane na ogromnych zbiorach tekstowych, co pozwala im analizować kontekst, odpowiadać na pytania, podsumowywać teksty, a nawet generować nowe treści. Modele te wykorzystują architekturę transformer, znaną z przełomowego modelu GPT (Generative Pre-trained Transformer) opracowanego przez OpenAI.
Na potrzeby tego artykułu będziemy używać modelu Gemma:2b. Gemma to seria modeli językowych opracowanych przez Google DeepMind, inspirowana zaawansowanymi modelami, takimi jak Bard i Gemini. Modele Gemma są zaprojektowane jako lekka alternatywa dla dużych modeli AI, umożliwiając wykorzystanie ich w środowiskach lokalnych oraz na urządzeniach o ograniczonych zasobach.
Aby pobrać model Gemma:2b wykonaj poniższe polecenie:
docker exec -it ollama_container ollama pull gemma:2bModel Gemma:2b bazuje na 2 miliardach parametrów i jego waga wynosi około 2GB. Po pobraniu całego modelu sprawdź czy jest on widoczny w Ollama wykonując polecenie:
docker exec -it ollama_container ollama listJako rezultat na ekranie powinna się pokazać lista ze wszystkimi dostępnymi modelami językowymi pobranymi na daną instancję Ollama:
NAME ID SIZE MODIFIED
gemma:2b b50d6c999e59 1.7 GB 1 day ago Ollama na Docker – Testowanie działania modelu
Najszybszym i zarazem najłatwiejszym sposobem na przetestowanie działania pobranego modelu jest wykonanie polecenia:
docker exec -it ollama_container ollama run gemma:2bSpowoduje ono uruchomienie modelu i umożliwienie użytkownikowi wprowadzenia prompta prosto z terminala.
# ollama run gemma:2b
>>> Send a message (/? for help)
Podsumowanie
Modele językowe LLM, takie jak Mistral i Gemma, otwierają nowe możliwości w zakresie przetwarzania języka naturalnego. Dzięki technologii Docker i narzędziom takim jak Ollama, można łatwo uruchomić je lokalnie, bez konieczności korzystania z komercyjnych API w chmurze. W tym artykule przedstawiliśmy, jak skonfigurować środowisko Docker do pracy z Ollama, pobrać wybrane modele i rozpocząć testowanie ich możliwości.
To dopiero początek serii artykułów, które pojawią się na naszym blogu. W kolejnych wpisach będziemy eksplorować bardziej zaawansowane aspekty pracy z LLM – od optymalizacji wydajności modeli po ich integrację z aplikacjami. Jeśli interesuje Cię, jak wykorzystać modele LLM w praktyce, śledź nasz blog, aby nie przegapić kolejnych części tej serii! 🚀
Jeśli interesujesz się tematem LLM to polecam przeczytanie poprzedniego artykułu o PLLuM!