
Modele LLM, czyli Large Language Model, to zaawansowana architektura AI, zaprojektowana do przetwarzania i generowania języka naturalnego. Modele te bazują na technikach głębokiego uczenia się, w szczególności na transformatorach (np. architektura GPT – Generative Pre-trained Transformer). LLM są szkolone na ogromnych zbiorach tekstowych, co pozwala im rozumieć kontekst, strukturę języka i generować odpowiedzi, które mogą być nieodróżnialne od tych tworzonych przez człowieka.
Modele LLM jako część sztucznej inteligencji
Modele LLM są częścią szerszej dziedziny sztucznej inteligencji, a dokładniej podkategorii zwaną przetwarzaniem języka naturalnego (NLP – Natural Language Processing). NLP koncentruje się na umożliwieniu maszynom rozumienia, interpretacji, generowania i analizowania języka ludzkiego. W ramach NLP, LLM wyróżniają się jako modele samouczenia, które potrafią działać bez konieczności ręcznego definiowania reguł językowych.
Modele LLM opierają się na głębokim uczeniu się, gałęzi uczenia maszynowego, która wykorzystuje sztuczne sieci neuronowe do rozpoznawania wzorców w ogromnych zbiorach danych tekstowych. Kluczową technologią wykorzystywaną w LLM są transformatory, które pozwalają modelom na przetwarzanie długich sekwencji tekstu poprzez mechanizm uwagi (attention mechanism). Dzięki temu LLM mogą analizować kontekst słów i zwrotów, co czyni je niezwykle skutecznymi w generowaniu spójnych i logicznych odpowiedzi.
Ponadto, LLM należą do klasy modeli predykcyjnych, co oznacza, że ich działanie polega na przewidywaniu najbardziej prawdopodobnej sekwencji słów na podstawie dostarczonych danych wejściowych. Nie są to jednak modele o rzeczywistym zrozumieniu języka, lecz statystyczne systemy analizy tekstu, które na podstawie ogromnych ilości danych uczą się wzorców komunikacyjnych.
Dzięki swojej zdolności do generowania i interpretacji języka naturalnego, LLM stanowią istotny element rozwoju sztucznej inteligencji kognitywnej, czyli systemów AI, które naśladują ludzkie zdolności poznawcze, takie jak analiza tekstu, rozwiązywanie problemów i podejmowanie decyzji na podstawie danych językowych.
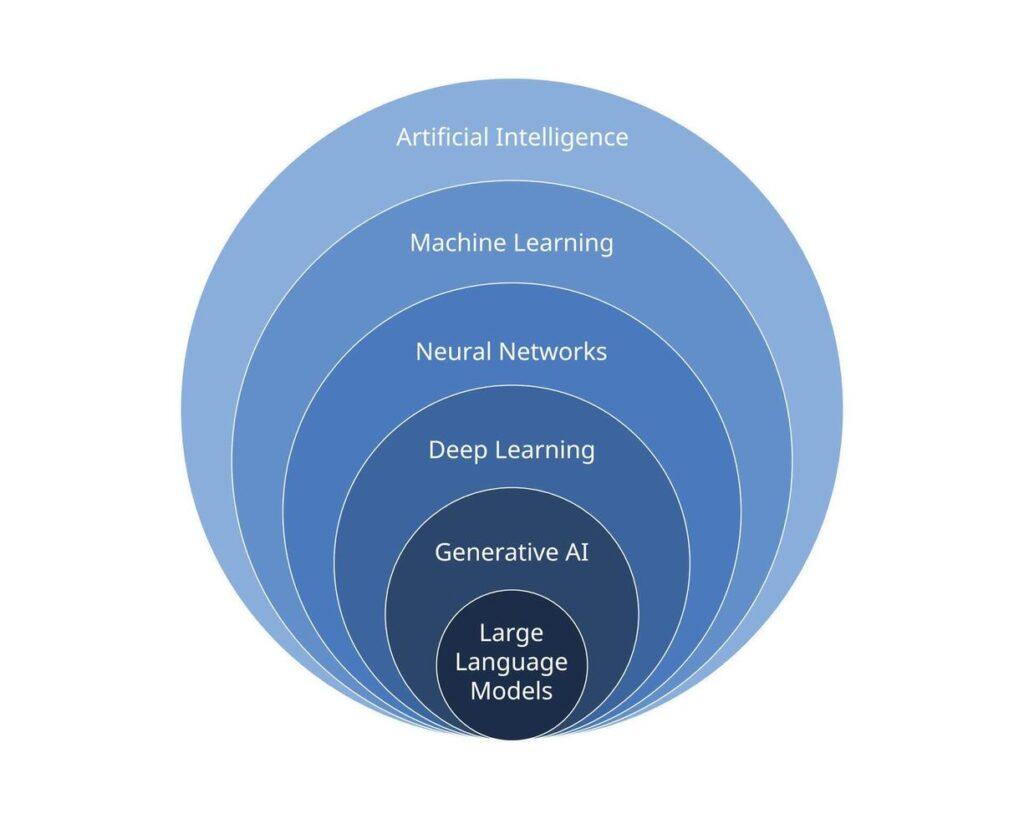
Podzbiory modeli LLM
LLM można podzielić na kilka podzbiorów w zależności od ich struktury, zastosowania i sposobu uczenia:
Modele specjalistyczne – dostosowane do konkretnych branż, takich jak medycyna (np. BioBERT) czy prawo, gdzie precyzja i znajomość specyficznego języka są kluczowe. Modele te są trenowane na specjalistycznych zbiorach danych, co pozwala im rozpoznawać i interpretować terminologię branżową. Na przykład w sektorze medycznym modele AI mogą analizować dokumentację medyczną, sugerować diagnozy czy wspomagać badania naukowe. W prawie mogą wspierać analizę precedensów, interpretację aktów prawnych oraz generowanie dokumentów zgodnych z wymaganiami legislacyjnymi.
Modele generatywne (np. GPT, LLaMA) – specjalizują się w generowaniu tekstu na podstawie podanego kontekstu. Wykorzystują ogromne zbiory danych do nauki wzorców językowych i relacji między słowami. Dzięki temu mogą tworzyć odpowiedzi, podsumowania, kreatywne treści, a nawet kod programistyczny. Modele generatywne są szeroko stosowane w chatbotach, systemach rekomendacyjnych oraz narzędziach do automatyzacji obsługi klienta. Potrafią także symulować dialogi w sposób naturalny, co czyni je nieocenionymi w asystentach głosowych i wirtualnych konsultantach.
Modele ekstrakcyjne (np. BERT, RoBERTa) – nie generują nowych treści, lecz analizują tekst i wyciągają z niego kluczowe informacje. Zostały zaprojektowane do zadań wymagających zrozumienia kontekstu, takich jak klasyfikacja tekstu, wyszukiwanie odpowiedzi w dokumentach czy analiza semantyczna. Modele te działają poprzez kodowanie tekstu w sposób, który umożliwia zrozumienie jego znaczenia w szerszym kontekście. Są stosowane w systemach wyszukiwania informacji, moderacji treści oraz w narzędziach analitycznych, które wymagają precyzyjnego przetwarzania dużych zbiorów danych.
Modele hybrydowe – łączą cechy modeli generatywnych i ekstrakcyjnych, umożliwiając zarówno generowanie, jak i analizę języka naturalnego. Przykładem mogą być systemy, które najpierw analizują dane wejściowe, wyciągają z nich istotne informacje, a następnie wykorzystują je do generowania odpowiedzi lub raportów. Modele hybrydowe znajdują zastosowanie w chatbotach o wysokiej precyzji, inteligentnych asystentach biznesowych oraz w systemach automatycznego streszczania dokumentów.
Dlaczego modele LLM zyskuje na popularności?
Popularność LLM rośnie w szybkim tempie ze względu na ich szerokie zastosowanie i rosnącą jakość generowanych treści. Istnieje kilka kluczowych czynników, które przyczyniają się do tego trendu:
- Rozwój technologii obliczeniowych – Wzrost mocy obliczeniowej oraz dostępność dedykowanych jednostek GPU i TPU sprawiają, że trenowanie i wdrażanie dużych modeli językowych jest coraz bardziej efektywne i opłacalne.
- Zwiększona dostępność danych – LLM czerpią wiedzę z ogromnych zbiorów danych dostępnych w Internecie, co pozwala im generować coraz bardziej precyzyjne i kontekstowe odpowiedzi. Bogactwo danych sprawia, że modele te mogą adaptować się do różnych zastosowań.
- Automatyzacja procesów biznesowych – Coraz więcej firm wdraża LLM do automatyzacji obsługi klienta, analizy danych, generowania raportów czy wspierania procesów kreatywnych. Dzięki temu przedsiębiorstwa mogą zwiększyć efektywność operacyjną i ograniczyć koszty związane z zatrudnianiem pracowników do powtarzalnych zadań.
- Zaawansowane możliwości w NLP – Modele LLM umożliwiają realizację zadań takich jak tłumaczenie językowe, streszczanie tekstów, analiza sentymentu czy generowanie treści na poziomie zbliżonym do ludzkiego. Dzięki temu ich użyteczność stale rośnie w różnych dziedzinach, od marketingu po naukę i medycynę.
- Integracja z popularnymi platformami i aplikacjami – Wiele firm technologicznych, takich jak OpenAI, Google czy Meta, integruje LLM z popularnymi usługami, co ułatwia ich adopcję w codziennym użytkowaniu. Przykłady to chatboty, inteligentni asystenci czy narzędzia do pisania i kodowania wspomagane przez AI.
Ograniczenia technologiczne w rozwoju modeli LLM
Pomimo dynamicznego rozwoju, LLM wciąż napotykają na istotne bariery technologiczne, które wpływają na ich działanie i dalszą ewolucję:
- Wysokie zapotrzebowanie na moc obliczeniową – Modele językowe wymagają ogromnych zasobów sprzętowych do treningu i działania. Trening zaawansowanych LLM może kosztować miliony dolarów i zajmować tygodnie na dedykowanych superkomputerach, co ogranicza ich dostępność dla mniejszych firm i badaczy.
- Zależność od dużych zbiorów danych – Jakość generowanych przez modele treści zależy od jakości danych, na których zostały wytrenowane. Jeśli dane wejściowe są stronnicze, nieaktualne lub zawierają błędy, model może odzwierciedlać te niedoskonałości w swoich odpowiedziach.
- Brak prawdziwego zrozumienia kontekstu – Pomimo swojej skuteczności, LLM nie posiadają rzeczywistego rozumienia tekstu, a jedynie przewidują najbardziej prawdopodobne sekwencje słów. To sprawia, że mogą generować odpowiedzi pozornie sensowne, ale w rzeczywistości niepoprawne lub niezgodne z faktami.
- Ograniczenia pamięci kontekstowej – Większość LLM ma ograniczoną liczbę tokenów, które mogą przetworzyć jednocześnie, co sprawia, że dłuższe konwersacje mogą tracić spójność, a modele mogą „zapominać” wcześniejsze informacje.
- Problemy etyczne i odpowiedzialność za treści – LLM mogą generować treści zawierające dezinformację, stronnicze opinie lub nieetyczne sugestie. Odpowiedzialność za treści wygenerowane przez AI stanowi istotne wyzwanie, zwłaszcza w kontekście dezinformacji, prywatności danych i regulacji prawnych.
- Trudności w interpretowalności i kontrolowaniu modeli – Ze względu na swoją złożoność, modele LLM działają jak tzw. „czarne skrzynki”, co oznacza, że trudno jest dokładnie przewidzieć, dlaczego generują określone odpowiedzi. To utrudnia ich kontrolowanie i korygowanie ewentualnych błędów.
Podsumowanie
Large Language Models zyskują na popularności dzięki swoim szerokim możliwościom zastosowania i rosnącej skuteczności w przetwarzaniu języka naturalnego. Jednak ich rozwój napotyka na wyzwania technologiczne, takie jak wysokie koszty obliczeniowe, ograniczenia w kontekście rozumienia treści oraz kwestie etyczne. Mimo to, ciągły postęp w dziedzinie sztucznej inteligencji i NLP sprawia, że LLM będą odgrywać coraz większą rolę w przyszłości technologii i komunikacji.