
Co to jest programowanie reaktywne?
Programowanie reaktywne, chociaż nie jest młodym konceptem, zaczyna ostatnio zyskiwać coraz większe zainteresowanie wśród programistów. A to za sprawą ReactiveX.io (Reactive Extension), który to spopularyzował to podejście poprzez stworzenie wielu bibliotek dostępnych w różnych językach programowania.
Idea programowania reaktywnego polega na zastosowaniu nieblokujących się mechanizmów, które podnoszą stabilność i wydajność aplikacji.
Programowanie imperatywne
Dla porównania koncepcja programowania imperatywnego (standardowe podejście blokujące, np. Spring MVC) polega na dedykowaniu konkretnego wątku do konkretnej operacji. Wątek ten jest zarezerwowany do obsługi żądania, począwszy od jego odebrania od klienta, poprzez wykonywanie logiki biznesowej aplikacji, a skończywszy na interakcji z bazą danych i odpowiedzi. Innymi słowy, jest zwalniany, dopiero gdy cały cykl życia danego żądania się zakończy.
Aplikacje działające imperatywnie posiadają określoną pulę wątków. Apache Tomcat standardowo posiada 200 wątków. Jeśli w danym czasie wszystkie są zajęte, to kolejne żądania muszą czekać na zwolnienie się aktualnie zajętych wątków. Oczywiście może to rodzić problemy wydajnościowe w aplikacjach przetwarzających duże ilości danych lub obsługujących dużą ilość żądań jednocześnie.
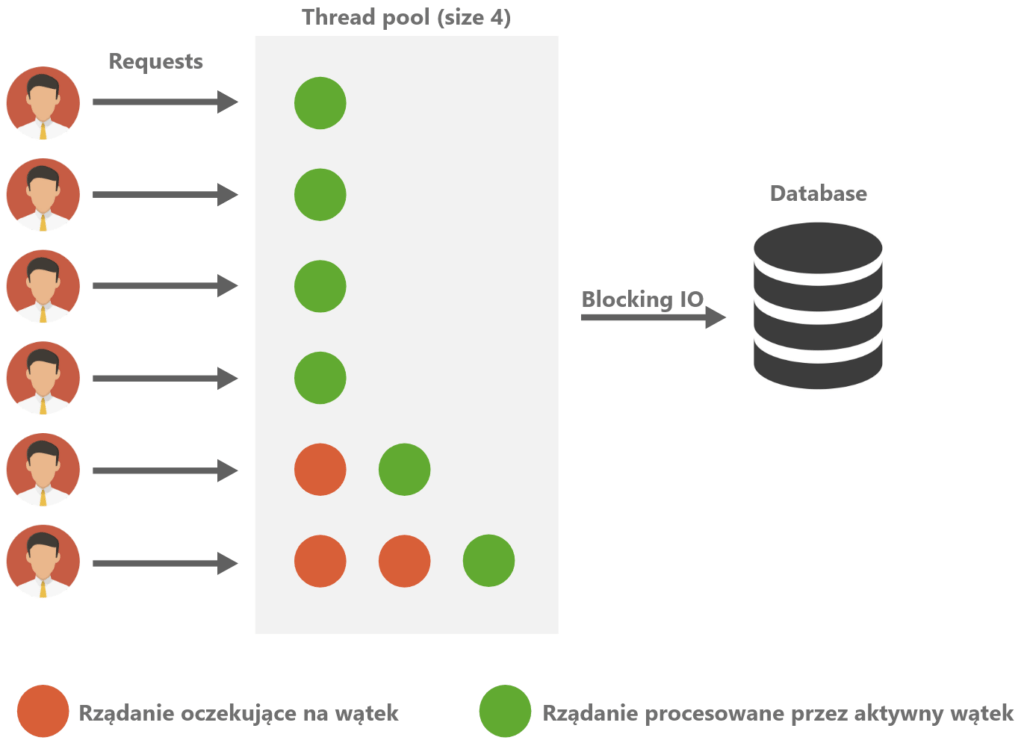
Przykład architekrury imperatywnej.
Programowanie reaktywne
W programowaniu reaktywnym (nieblokującym) wątek odbierający żądanie jest zwalniany jeszcze przed wysłaniem odpowiedzi do klienta. Dzięki takiemu podejściu może obsłużyć kolejne żądanie. Przetwarzanie żądań delegowanych przez wątek odbierający odbywa się asynchronicznie. Odpowiedź na żądanie jest odsyłana do klienta za pomocą zdarzeń.
Ilość wątków odpierających żądania jest uzależniona od architektury procesora. Zazwyczaj jest ich mniej więcej tyle samo co rdzeni w procesorze. To dosyć mało w porównaniu do stylu imperatywnego. Jednak tutaj wątek odbierający nie jest blokowany i nie czeka na przetworzenie całego żądania w celu odesłania odpowiedzi klientowi.

Przykład architektury reaktywnej.
Programowanie reaktywne jest zaprojektowane na podstawie wzorca Obserwator. Są w nim wykorzystywane odpowiednie obiekty „Publisher” i „Subscriber”.
„Publisher” ma za zadanie wyprodukować dane, o których informuje obiekt „Subscriber”. Ten drugi za to konsumuję dane wyprodukowane przez obiekt „Publisher”. Całość zazwyczaj opiera się o mechanizm „callback’ów”.
Programowanie reaktywne – Backpressure
„Subscriber” podczas konsumowania danych emitowanych przez „Publisher’a” może mieć problemy z ich przetwarzaniem czy to związane z logiką biznesową, czy też ze swoją wydajnością. W tym celu zaprojektowano mechanizm „Backpressure”. Jest on odpowiedzialny za komunikację pomiędzy „Subscriber’em” i „Publisherem” z tym, że tutaj to „Subscriber” wysyła wiadomości, a nie je konsumuje. Komunikacja ta nie jest wykorzystywana za każdym odebraniem eventu, lecz jest „on demand” (na żądanie). Backpressure jest wykorzystywany, tylko jeśli jest on faktycznie potrzebny.
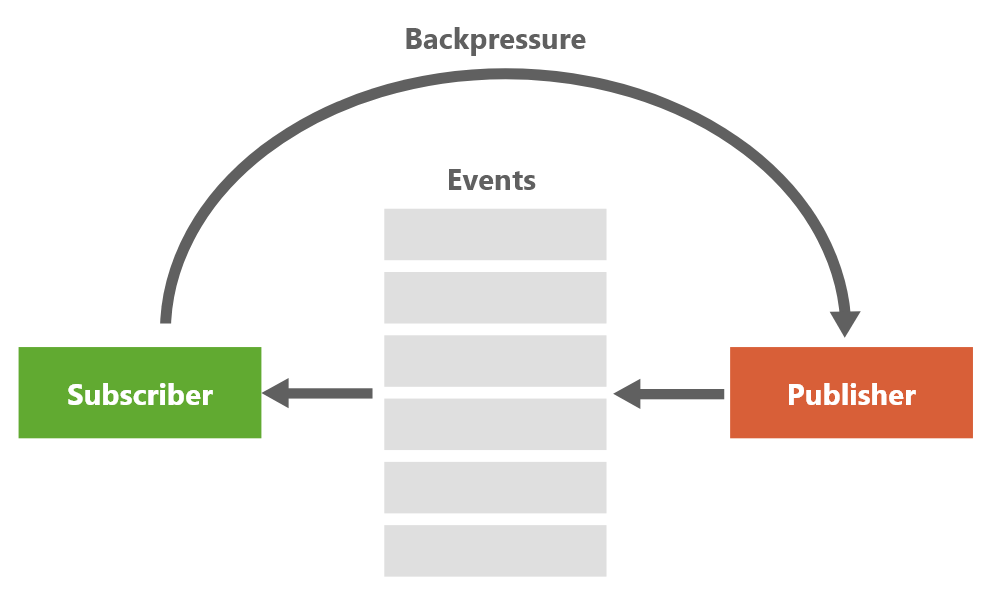
Schemat działania Backpressure.
Kiedy użyć programowania reaktywnego?
Podejście reaktywne nie niesie za sobą oszałamiającego wzrostu wydajności aplikacji. Raczej wynosi on maksymalnie od kilku do kilkunastu procent. Jednak dzięki niemu system staje się stabilniejszy przy dużym obciążeniu.
Sprawdzi się bardzo dobrze w systemach klasy enterprise, które przetwarzają ogromne ilości danych lub obsługują jednorazowo dużą ilość zapytań.
Można go użyć także w programowaniu aplikacji w architekturze mikroserwisowej, gdzie poszczególne serwisy wymieniają między sobą dużą ilość informacji. Dzięki programowaniu reaktywnemu wątek mikroserwisu po odebraniu żądania nie czeka „zablokowany” aż do momentu, gdy je przetworzy i odeślę odpowiedź, leczy jest wstanie przyjąć kolejne żądanie.
Nowe systemy, pisane od zera są dobrym miejscem na wprowadzenie podejścia reaktywnego. Możemy wtedy zaprojektować czystą architekturę, która używa mechanizmów „non-blocking” do komunikacji z klientami czy też bazą danych.
Kiedy NIE używać programowania reaktywnego?
Nie zawsze użycie paradygmatu programowania reaktywnego może okazać się trafnym wyborem.
Jak masz młotek, to wszędzie widzisz gwoździe!
Jeśli aplikacja legacy posiada problemy wydajnościowe, to lepszym rozwiązaniem będzie na początku optymalizacja aktualnego kodu, bazy danych czy też architektury. Dopiero, jeśli to nie przyniesie oczekiwanej poprawny, to możemy pokusić się o wprowadzenie mechanizmów programowania reaktywnego.
Samo programowania reaktywne jest znacznie bardziej złożone od podejścia imperatywnego. Implementacja go bez wyraźnej konieczności może niepotrzebnie przynieść negatywne efekty w formie zwiększenia poziomu skomplikowania aplikacji, jej utrzymania oraz progu wejścia dla nowych członków zespołu.
Podsumowanie
Jak widać, wszystko ma swoje plusy i minusy. Nie zawsze wprowadzenie programowania reaktywnego w projekcie może być uzasadnione. Warto wcześniej sprawdzić inne drogi optymalizacji, jeśli mówimy tutaj o projektach już działających.
Mam nadzieję, że chociaż w małym stopniu przedstawiłem Ci paradygmat programowania reaktywnego.
Dowiedz się więcej na ten temat:
Jeśli podobał Ci się ten artykuł, to podziel się nim w swoich social mediach! Zachęcam Cię też do pozostawienia swojej opinii w komentarzu.